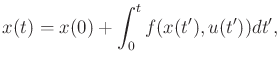Next: 14.1.2 Different Kinds of Up: 14.1 Introduction Previous: 14.1 Introduction
Motion planning under differential constraints can be considered as a variant of classical two-point boundary value problems (BVPs) [440]. In that setting, initial and goal states are given, and the task is to compute a path through a state space that connects initial and goal states while satisfying differential constraints. Motion planning involves the additional complication of avoiding obstacles in the state space. Techniques for solving BVPs are unfortunately not well-suited for motion planning because they are not designed for handling obstacle regions. For some methods, adaptation may be possible; however, the obstacle constraints usually cause these classical methods to become inefficient or incomplete. Throughout this chapter, the BVP will refer to motion planning with differential constraints and no obstacles. BVPs that involve more than two points also exist; however, they are not considered in this book.
It is assumed that the differential constraints are expressed in a
state transition equation,
![]() , on a smooth manifold
, on a smooth manifold
![]() , called the state space, which may be a C-space
, called the state space, which may be a C-space ![]() or a
phase space of a C-space. A solution path will not be directly
expressed as in Part II but is instead derived from an
action trajectory via integration of the state transition equation.
or a
phase space of a C-space. A solution path will not be directly
expressed as in Part II but is instead derived from an
action trajectory via integration of the state transition equation.
Let the action space ![]() be a bounded subset of
be a bounded subset of
![]() . A planning
algorithm computes an action trajectory
. A planning
algorithm computes an action trajectory
![]() , which is a
function of the form
, which is a
function of the form
![]() . The action
at a particular time
. The action
at a particular time ![]() is expressed as
is expressed as ![]() . To be consistent
with standard notation for functions, it seems that this should
instead be denoted as
. To be consistent
with standard notation for functions, it seems that this should
instead be denoted as
![]() . This abuse of notation was
intentional, to make the connection to the discrete-stage case
clearer and to distinguish an action,
. This abuse of notation was
intentional, to make the connection to the discrete-stage case
clearer and to distinguish an action, ![]() , from an action
trajectory
, from an action
trajectory
![]() . If the action space is state-dependent, then
. If the action space is state-dependent, then
![]() must additionally satisfy
must additionally satisfy
![]() . For
state-dependent models, this will be assumed by default. It will also
be assumed that a termination action
. For
state-dependent models, this will be assumed by default. It will also
be assumed that a termination action ![]() is used, which makes it
possible to specify all action trajectories over
is used, which makes it
possible to specify all action trajectories over
![]() with the
understanding that at some time
with the
understanding that at some time ![]() , the termination action is
applied.
, the termination action is
applied.
The connection between the action and state trajectories needs to be
formulated. Starting from some initial state ![]() at time
at time ![]() ,
a state trajectory is derived from an action trajectory
,
a state trajectory is derived from an action trajectory
![]() as
as
The problem of motion planning under differential constraints can be formulated as an extension of the Piano Mover's Problem in Formulation 4.1. The main differences in this extension are 1) the introduction of time, 2) the state or phase space, and 3) the state transition equation. The resulting formulation follows.
A final time does not need to be stated because of the termination
action ![]() . As usual, once
. As usual, once ![]() is applied, cost does not
accumulate any further and the state remains fixed. This might seem
strange for problems that involve dynamics because momentum should
keep the state in motion. Keep in mind that the termination action is
a trick to make the formulation work correctly. In many cases, the
goal corresponds to a subset of
is applied, cost does not
accumulate any further and the state remains fixed. This might seem
strange for problems that involve dynamics because momentum should
keep the state in motion. Keep in mind that the termination action is
a trick to make the formulation work correctly. In many cases, the
goal corresponds to a subset of ![]() in which the velocity components
are zero. In this case, there is no momentum and hence no problem.
If the goal region includes states that have nonzero velocity, then it
is true that a physical system may keep moving after
in which the velocity components
are zero. In this case, there is no momentum and hence no problem.
If the goal region includes states that have nonzero velocity, then it
is true that a physical system may keep moving after ![]() has been
applied; however, the cost functional will not measure any additional
cost. The task is considered to be completed after
has been
applied; however, the cost functional will not measure any additional
cost. The task is considered to be completed after ![]() is applied,
and the simulation is essentially halted. If the mechanical system
eventually collides due to momentum, then this is the problem of the
user who specified a goal state that involves momentum.
is applied,
and the simulation is essentially halted. If the mechanical system
eventually collides due to momentum, then this is the problem of the
user who specified a goal state that involves momentum.
The overwhelming majority of solution techniques are sampling-based.
This is motivated primarily by the extreme difficultly of planning
under differential constraints. The standard Piano Mover's
Problem from Formulation 4.1 is a special case of
Formulation 14.1 and is already PSPACE-hard [817].
Optimal planning is also NP-hard, even for a point in a 3D polyhedral
environment without differential constraints [172]. The
only known methods for exact planning under differential constraints
in the presence of obstacles are for the double integrator
system
![]() , for
, for
![]() [747] and
[747] and
![]() [171].
[171].
Section 14.1.2 provides some perspective on motion planning problems under differential constraints that fall under Formulation 14.1, which assumes that the initial state is given and future states are predictable. Section 14.5 briefly addresses the broader problem of feedback motion planning under differential constraints.
Steven M LaValle 2020-08-14