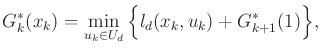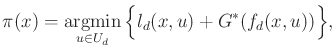Next: 14.6 Decoupled Planning Approaches Up: 14.5 Feedback Planning Under Previous: 14.5.1 Problem Definition
As observed in Section 14.4, motion planning under
differential constraints is extremely challenging. Additionally
requiring feedback complicates the problem even further. If
![]() , then a feedback plan can be designed using numerous
techniques from control theory. See Section 15.2.2 and
[192,523,846]. In many cases, designing feedback plans is
no more difficult than computing an open-loop trajectory. However, if
, then a feedback plan can be designed using numerous
techniques from control theory. See Section 15.2.2 and
[192,523,846]. In many cases, designing feedback plans is
no more difficult than computing an open-loop trajectory. However, if
![]() , feedback usually makes the problem much
harder.
, feedback usually makes the problem much
harder.
Fortunately, dynamic programming once again comes to the rescue. In
Section 2.3, value iteration yielded feedback plans for
discrete state spaces and state transition equations. It is
remarkable that this idea can be generalized to the case in which ![]() and
and ![]() are continuous and there is a continuum of stages (called
time). Most of the tools required to apply dynamic programming in the
current setting were already introduced in Section 8.5.2.
The main ideas in that section were to represent the optimal
cost-to-go
are continuous and there is a continuum of stages (called
time). Most of the tools required to apply dynamic programming in the
current setting were already introduced in Section 8.5.2.
The main ideas in that section were to represent the optimal
cost-to-go ![]() by interpolation and to use a
discrete-time approximation to the motion planning problem.
by interpolation and to use a
discrete-time approximation to the motion planning problem.
The discrete-time model of Section 14.2.2 can be used in the
current setting to obtain a discrete-stage state transition equation
of the form
![]() . The cost functional is
approximated as in Section 8.5.2 by using
(8.65). This integral can be evaluated numerically
by using the result of the system simulator and yields the
cost-per-stage as
. The cost functional is
approximated as in Section 8.5.2 by using
(8.65). This integral can be evaluated numerically
by using the result of the system simulator and yields the
cost-per-stage as
![]() . Using backward value iteration, the
dynamic programming recurrence is
. Using backward value iteration, the
dynamic programming recurrence is
As in Section 8.5.2, a set
![]() of samples is
used to approximate
of samples is
used to approximate ![]() over
over ![]() . The required values at points
in
. The required values at points
in
![]() are obtained by interpolation. For example, the
barycentric subdivision scheme of Figure 8.20 may be
applied here to interpolate over simplexes in
are obtained by interpolation. For example, the
barycentric subdivision scheme of Figure 8.20 may be
applied here to interpolate over simplexes in
![]() time, in
which
time, in
which ![]() is the dimension of
is the dimension of ![]() .
.
As usual, backward value iteration starts at some final stage ![]() and proceeds backward through the stage indices. Termination occurs
when all of the cost-to-go values stabilize. The initialization
at stage
and proceeds backward through the stage indices. Termination occurs
when all of the cost-to-go values stabilize. The initialization
at stage ![]() yields
yields
![]() for
for
![]() ;
otherwise,
;
otherwise,
![]() . Each subsequent iteration is
performed by evaluating (14.27) on each
. Each subsequent iteration is
performed by evaluating (14.27) on each ![]() and
using interpolation to obtain
and
using interpolation to obtain
![]() .
.
The resulting stationary cost-to-go function ![]() can serve
as a navigation function over
can serve
as a navigation function over
![]() , as described in Section
8.5.2. Recall from Chapter 8 that a
navigation function is converted into a feedback plan by applying a
local operator. The local operator in the
present setting is
, as described in Section
8.5.2. Recall from Chapter 8 that a
navigation function is converted into a feedback plan by applying a
local operator. The local operator in the
present setting is
Unfortunately, the method presented here is only useful in spaces of a
few dimensions. If
![]() , then it may be applied, for example, to
the systems in Section 13.1.2. If dynamics are considered,
then in many circumstances the dimension is too high because the
dimension of
, then it may be applied, for example, to
the systems in Section 13.1.2. If dynamics are considered,
then in many circumstances the dimension is too high because the
dimension of ![]() is usually twice that of
is usually twice that of ![]() . For example, if
. For example, if ![]() is a rigid body in the plane, then the dimension of
is a rigid body in the plane, then the dimension of ![]() is six, which
is already at the usual limit of practical use.
is six, which
is already at the usual limit of practical use.
It is interesting to compare the use of dynamic programming here with
that of Sections 14.4.1 and 14.4.2, in which a
search graph was constructed. If Dijkstra's algorithm is used
(or even breadth-first search in the case of time optimality), then by
the dynamic programming principle, the resulting solutions are
approximately optimal. To ensure convergence, resolution completeness
arguments were given based on Lipschitz conditions on ![]() . It was important to allow the resolution to
improve as the search failed to find a solution. Instead of computing
a search graph, value iteration is based on computing cost-to-go
functions. In the same way that both forward and backward versions
of the tree-based approaches were possible, both forward and backward
value iteration can be used here. Providing resolution completeness
is more difficult, however, because
. It was important to allow the resolution to
improve as the search failed to find a solution. Instead of computing
a search graph, value iteration is based on computing cost-to-go
functions. In the same way that both forward and backward versions
of the tree-based approaches were possible, both forward and backward
value iteration can be used here. Providing resolution completeness
is more difficult, however, because ![]() is not fixed. It is
therefore not known whether some resolution is good enough for the
intended application. If
is not fixed. It is
therefore not known whether some resolution is good enough for the
intended application. If ![]() is known, then
is known, then ![]() can be used
to generate a trajectory from
can be used
to generate a trajectory from ![]() using the system simulator. If
the trajectory fails to reach
using the system simulator. If
the trajectory fails to reach ![]() , then the resolution can be
improved by adding more samples to
, then the resolution can be
improved by adding more samples to ![]() and
and ![]() or by reducing
or by reducing
![]() . Under Lipschitz conditions on
. Under Lipschitz conditions on ![]() , the approach converges
to the true optimal cost-to-go [92,168,565].
Therefore, value iteration can be considered resolution complete with
respect to a given
, the approach converges
to the true optimal cost-to-go [92,168,565].
Therefore, value iteration can be considered resolution complete with
respect to a given ![]() . The convergence even extends to
computing optimal feedback plans with additional actions that are
taken by nature, which is modeled nondeterministically or
probabilistically. This extends the value iteration method of Section
10.6.
. The convergence even extends to
computing optimal feedback plans with additional actions that are
taken by nature, which is modeled nondeterministically or
probabilistically. This extends the value iteration method of Section
10.6.
The relationship between the methods based on a search graph and on
value iteration can be brought even closer by constructing
Dijkstra-like versions of value iteration, as described at the end of
Section 8.5.2. These extend Dijkstra's algorithm,
which was viewed for the finite case in Section 2.3.3 as an
improvement to value iteration. The improvement to value iteration is
made by recognizing that in most evaluations of
(14.27), the cost-to-go value does not change.
This is caused by two factors: 1) From some states, no trajectory has
yet been found that leads to ![]() ; therefore, the cost-to-go
remains at infinity. 2) The optimal cost-to-go from some state might
already be computed; no future iterations would improve the cost.
; therefore, the cost-to-go
remains at infinity. 2) The optimal cost-to-go from some state might
already be computed; no future iterations would improve the cost.
A forward or backward version of a Dijkstra-like algorithm can be
made. Consider the backward case. The notion of a backprojection was
used in Section 8.5.2 to characterize the set of states
that can reach another set of states in one stage. This was used in
(8.68) to define the frontier
during the execution of the Dijkstra-like algorithm. There is
essentially no difference in the current setting to handle the system
![]() . Once the discrete-time approximation has been made,
the definition of the backprojection is essentially the same as in
(8.66) of Section 8.5.2. Using the
discrete-time model of Section 14.2.2, the
backprojection of a state
. Once the discrete-time approximation has been made,
the definition of the backprojection is essentially the same as in
(8.66) of Section 8.5.2. Using the
discrete-time model of Section 14.2.2, the
backprojection of a state
![]() is
is