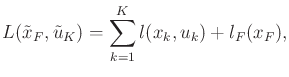Next: Feasibility and optimality Up: 8.2 Discrete State Spaces Previous: 8.2 Discrete State Spaces
Consider a discrete planning problem similar to the ones defined in
Formulations 2.1 and 2.3, except that the initial
state is not given. Due to this, the cost functional cannot be
expressed only as a function of a plan. It is instead defined in
terms of the state history and action history. At stage
![]() , these are defined as
, these are defined as
| (8.1) |
| (8.2) |
The resulting formulation is
Consider defining a plan that solves Formulation 8.1. If
the initial condition is given, then a sequence of actions could be
specified, as in Chapter 2. Without having the
initial condition, one possible approach is to determine a sequence of
actions for each possible initial state, ![]() . Once the
initial state is given, the appropriate action sequence is known.
This approach, however, wastes memory. Suppose some
. Once the
initial state is given, the appropriate action sequence is known.
This approach, however, wastes memory. Suppose some ![]() is given as
the initial state and the first action is applied, leading to the next
state
is given as
the initial state and the first action is applied, leading to the next
state ![]() . What action should be applied from
. What action should be applied from ![]() ? The second
action in the sequence at
? The second
action in the sequence at ![]() can be used; however, we can also
imagine that
can be used; however, we can also
imagine that ![]() is now the initial state and use its first action.
This implies that keeping an action sequence for every state is highly
redundant. It is sufficient at each state to keep only the first
action in the sequence. The application of that action produces the
next state, at which the next appropriate action is stored. An
execution sequence can be imagined from an initial state as follows.
Start at some state, apply the action stored there, arrive at another
state, apply its action, arrive at the next state, and so on, until
the goal is reached.
is now the initial state and use its first action.
This implies that keeping an action sequence for every state is highly
redundant. It is sufficient at each state to keep only the first
action in the sequence. The application of that action produces the
next state, at which the next appropriate action is stored. An
execution sequence can be imagined from an initial state as follows.
Start at some state, apply the action stored there, arrive at another
state, apply its action, arrive at the next state, and so on, until
the goal is reached.
It therefore seems appropriate to represent a feedback plan as a
function that maps every state to an action. Therefore, a
feedback plan ![]() is defined as a function
is defined as a function
![]() . From every state,
. From every state, ![]() , the plan indicates which
action to apply. If the goal is reached, then the termination action
should be applied. This is specified as part of the plan:
, the plan indicates which
action to apply. If the goal is reached, then the termination action
should be applied. This is specified as part of the plan:
![]() , if
, if
![]() . A feedback plan is called a solution
to the problem if it causes the goal to be reached from every state
that is reachable from the goal.
. A feedback plan is called a solution
to the problem if it causes the goal to be reached from every state
that is reachable from the goal.
If an initial state ![]() and a feedback plan
and a feedback plan ![]() are given, then
the state and action histories can be determined. This implies that
the execution cost, (8.3), also can be determined. It
can therefore be alternatively expressed as
are given, then
the state and action histories can be determined. This implies that
the execution cost, (8.3), also can be determined. It
can therefore be alternatively expressed as
![]() , instead
of
, instead
of
![]() . This relies on future states always being
predictable. In Chapter 10, it will not be possible to
make this direct correspondence due to uncertainties (see Section
10.1.3).
. This relies on future states always being
predictable. In Chapter 10, it will not be possible to
make this direct correspondence due to uncertainties (see Section
10.1.3).