Next: 11.7.2 Information Spaces for Up: 11.7 Information Spaces in Previous: 11.7 Information Spaces in
Recall from Section 10.5.1 that an important part of formulating a sequential game in a game tree is specifying the information model. This was described in Step 4 of Formulation 10.3. Three information models were considered in Section 10.5.1: alternating play, stage-by-stage, and open loop. These and many other information models can be described using I-spaces.
From Section 11.1, it should be clear that an I-space is
always defined with respect to a state space. Even though Section
10.5.1 did not formally introduce a state space, it is
not difficult to define one. Let the state space ![]() be
be ![]() , the
set of all vertices in the game tree. Assume that two players are
engaged in a sequential zero-sum game. Using notation from Section
10.5.1,
, the
set of all vertices in the game tree. Assume that two players are
engaged in a sequential zero-sum game. Using notation from Section
10.5.1, ![]() and
and ![]() are the decision vertices of
are the decision vertices of
![]() and
and
![]() , respectively. Consider the nondeterministic I-space
, respectively. Consider the nondeterministic I-space
![]() over
over ![]() . Let
. Let ![]() denote a nondeterministic I-state;
thus, each
denote a nondeterministic I-state;
thus, each
![]() is a subset of
is a subset of ![]() .
.
There are now many possible ways in which the players can be confused
while making their decisions. For example, if some ![]() contains
vertices from both
contains
vertices from both ![]() and
and ![]() , the player does not know whether
it is even its turn to make a decision. If
, the player does not know whether
it is even its turn to make a decision. If ![]() additionally
contains some leaf vertices, the game may be finished without a player
even being aware of it. Most game tree formulations avoid these
strange situations. It is usually assumed that the players at least
know when it is their turn to make a decision. It is also usually
assumed that they know the stage of the game. This eliminates many
sets from
additionally
contains some leaf vertices, the game may be finished without a player
even being aware of it. Most game tree formulations avoid these
strange situations. It is usually assumed that the players at least
know when it is their turn to make a decision. It is also usually
assumed that they know the stage of the game. This eliminates many
sets from
![]() .
.
While playing the game, each player has its own nondeterministic
I-state because the players may hide their decisions from each other.
Let ![]() and
and ![]() denote the nondeterministic I-states for
denote the nondeterministic I-states for
![]() and
and
![]() , respectively. For each player, many sets in
, respectively. For each player, many sets in
![]() are eliminated. Some are removed to avoid the confusions
mentioned above. We also impose the constraint that
are eliminated. Some are removed to avoid the confusions
mentioned above. We also impose the constraint that
![]() for
for ![]() and
and ![]() . We only care about the I-state of a
player when it is that player's turn to make a decision. Thus, the
nondeterministic I-state should tell us which decision vertices in
. We only care about the I-state of a
player when it is that player's turn to make a decision. Thus, the
nondeterministic I-state should tell us which decision vertices in
![]() are possible as
are possible as
![]() faces a decision. Let
faces a decision. Let
![]() and
and
![]() represent the nondeterministic I-spaces for
represent the nondeterministic I-spaces for
![]() and
and
![]() ,
respectively, with all impossible I-states eliminated.
,
respectively, with all impossible I-states eliminated.
The I-spaces
![]() and
and
![]() are usually defined directly on
the game tree by circling vertices that belong to the same I-state.
They form a partition of the vertices in each level of the tree
(except the leaves). In fact,
are usually defined directly on
the game tree by circling vertices that belong to the same I-state.
They form a partition of the vertices in each level of the tree
(except the leaves). In fact,
![]() even forms a partition of
even forms a partition of
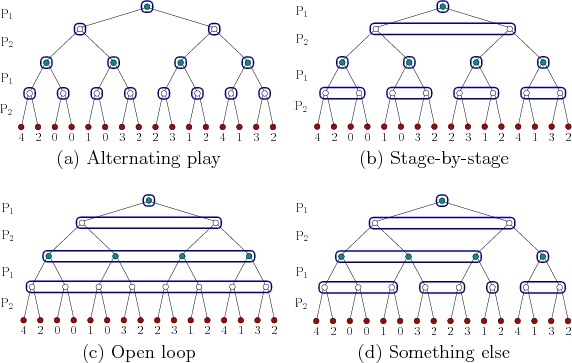
![]() for each player. Figure 11.30 shows four information
models specified in this way for the example in Figure
10.13. The first three correspond directly to the models
allowed in Section 10.5.1. In the alternating-play
model, each player always knows the
decision vertex. This corresponds to a case of perfect state
information. In the stage-by-stage model,
for each player. Figure 11.30 shows four information
models specified in this way for the example in Figure
10.13. The first three correspond directly to the models
allowed in Section 10.5.1. In the alternating-play
model, each player always knows the
decision vertex. This corresponds to a case of perfect state
information. In the stage-by-stage model,
![]() always knows the decision vertex;
always knows the decision vertex;
![]() knows the
decision vertex from which
knows the
decision vertex from which
![]() made its last decision, but it does
not know which branch was chosen. The open-loop
model represents the case that has the
poorest information. Only
made its last decision, but it does
not know which branch was chosen. The open-loop
model represents the case that has the
poorest information. Only
![]() knows its decision vertex at the
beginning of the game. After that, there is no information about the
actions chosen. In fact, the players cannot even remember their own
previous actions. Figure 11.30d shows an information
model that does not fit into any of the three previous ones. In this
model, very strange behavior results. If
knows its decision vertex at the
beginning of the game. After that, there is no information about the
actions chosen. In fact, the players cannot even remember their own
previous actions. Figure 11.30d shows an information
model that does not fit into any of the three previous ones. In this
model, very strange behavior results. If
![]() and
and
![]() initially
choose right branches, then the resulting decision vertex is known;
however, if
initially
choose right branches, then the resulting decision vertex is known;
however, if
![]() instead chooses the left branch, then
instead chooses the left branch, then
![]() will
forget which action it applied (as if the action of
will
forget which action it applied (as if the action of
![]() caused
caused
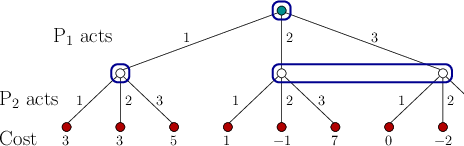
![]() to have amnesia!). Here is a single-stage example:
to have amnesia!). Here is a single-stage example:
Plans are now defined directly as functions on the I-spaces. A (deterministic) plan for
![]() is defined
as a function
is defined
as a function ![]() on
on
![]() that yields an action
that yields an action
![]() for each
for each
![]() , and
, and
![]() is the set of
actions that can be inferred from the I-state
is the set of
actions that can be inferred from the I-state ![]() ; assume that
this set is the same for all decision vertices in
; assume that
this set is the same for all decision vertices in ![]() .
Similarly, a (deterministic) plan for
.
Similarly, a (deterministic) plan for
![]() is defined as a
function
is defined as a
function ![]() on
on
![]() that yields an action
that yields an action
![]() for each
for each
![]() .
.
There are generally two alternative ways to define a randomized plan
in terms of I-spaces. The first choice is to define a globally
randomized plan, which is a probability distribution over the set of
all deterministic plans. During execution, this means that an entire
deterministic plan will be sampled in advance according to the
probability distribution. An alternative is to sample actions as they
are needed at each I-state. This is defined as follows. For the
randomized case, let
![]() and
and
![]() denote the sets of
all probability distributions over
denote the sets of
all probability distributions over
![]() and
and
![]() ,
respectively. A locally randomized plan for
,
respectively. A locally randomized plan for
![]() is defined as
a function that yields some
is defined as
a function that yields some
![]() for each
for each
![]() . Likewise, a locally
randomized plan for
. Likewise, a locally
randomized plan for
![]() is a function that maps from
is a function that maps from
![]() into
into
![]() . Locally randomized plans expressed as functions of
I-states are often called behavioral strategies in game theory
literature.
. Locally randomized plans expressed as functions of
I-states are often called behavioral strategies in game theory
literature.
A randomized saddle point on the space of locally randomized plans
does not exist for all sequential games [59]. This is
unfortunate because this form of randomization seems most natural for
the way decisions are made during execution. At least for the
stage-by-stage model, a randomized saddle point always exists on the
space of locally randomized plans. For the open-loop model,
randomized saddle points are only guaranteed to exist using a globally
randomized plan (this was actually done in Section
10.5.1). To help understand the problem, suppose that
the game tree is a balanced, binary tree with ![]() stages (hence,
stages (hence, ![]() levels). For each player, there are
levels). For each player, there are ![]() possible deterministic
plans. This means that
possible deterministic
plans. This means that ![]() probability values may be assigned
independently (the last one is constrained to force them to sum to
probability values may be assigned
independently (the last one is constrained to force them to sum to
![]() ) to define a globally randomized plan over the space of
deterministic plans. Defining a locally randomized plan, there are
) to define a globally randomized plan over the space of
deterministic plans. Defining a locally randomized plan, there are
![]() I-states for each player, one for each search stage. At each
stage, a probability distribution is defined over the action set,
which contains only two elements. Thus, each of these distributions
has only one independent parameter. A randomized plan is specified in
this way using
I-states for each player, one for each search stage. At each
stage, a probability distribution is defined over the action set,
which contains only two elements. Thus, each of these distributions
has only one independent parameter. A randomized plan is specified in
this way using ![]() independent parameters. Since
independent parameters. Since ![]() is much less
than
is much less
than ![]() , there are many globally randomized plans that cannot be
expressed as a locally randomized plan. Unfortunately, in some games
the locally randomized representation removes the randomized saddle
point.
, there are many globally randomized plans that cannot be
expressed as a locally randomized plan. Unfortunately, in some games
the locally randomized representation removes the randomized saddle
point.
This strange result arises mainly because players can forget information over time. A player with perfect recall remembers its own actions and also never forgets any information that it previously knew. It was shown by Kuhn that the space of all globally randomized plans is equivalent to the space of all locally randomized plans if and only if the players have perfect memory [562]. Thus, by sticking to games in which all players have perfect recall, a randomized saddle point always exists in the space locally randomized plans. The result of Kuhn even holds for the more general case of the existence of randomized Nash equilibria on the space of locally randomized plans.
The nondeterministic I-states can be used in game trees that involve more players. Accordingly, deterministic, globally randomized, and locally randomized plans can be defined. The result of Kuhn applies to any number of players, which ensures the existence of a randomized Nash equilibrium on the space of locally randomized strategies if (and only if) the players have perfect recall. It is generally preferable to exploit this fact and decompose the game tree into smaller matrix games, as described in Section 10.5.1. It turns out that the precise condition that allows this is that it must be ladder-nested [59]. This means that there are decision vertices, other than the root, at which 1) the player that must make a decision knows it is at that vertex (the nondeterministic I-state is a singleton set), and 2) the nondeterministic I-state will not leave the subtree rooted at that vertex (vertices outside of the subtree cannot be circled when drawing the game tree). In this case, the game tree can be decomposed at these special decision vertices and replaced with the game value(s). Unfortunately, there is still the nuisance of multiple Nash equilibria.
It may seem odd that nondeterministic I-states were defined without
being derived from a history I-space. Without much difficulty, it is
possible to define a sensing model that leads to the nondeterministic
I-states used in this section. In many cases, the I-state can be
expressed using only a subset of the action histories. Let
![]() and
and
![]() denote the action histories of
denote the action histories of
![]() and
and
![]() ,
respectively. The history I-state for the alternating-play model at
stage
,
respectively. The history I-state for the alternating-play model at
stage ![]() is
is
![]() for
for
![]() and
and
![]() for
for
![]() . The history I-state for the
stage-by-stage model is
. The history I-state for the
stage-by-stage model is
![]() for both
players. The nondeterministic I-states used in this section can be
derived from these histories. For other models, such as the one in
Figure 11.31, a sensing model is additionally needed
because only partial information regarding some actions appears. This
leads into the formulation covered in the next section, which involves
both sensing models and a state space.
for both
players. The nondeterministic I-states used in this section can be
derived from these histories. For other models, such as the one in
Figure 11.31, a sensing model is additionally needed
because only partial information regarding some actions appears. This
leads into the formulation covered in the next section, which involves
both sensing models and a state space.