Next: 10.5.2 Sequential Games on Up: 10.5.1 Game Trees Previous: 10.5.1.2 Computing a saddle
Up to this point, solutions have been determined for the
alternating-play and the stage-by-stage models. The open-loop model
remains. In this case, there is no exchange of information between
the players until the game is finished and they receive their costs.
Therefore, imagine that players engaged in such a sequential game are
equivalently engaged in a large, single-stage game. Recall that a
plan under the open-loop model is a function over ![]() . Let
. Let
![]() and
and ![]() represent the sets of possible plans for
represent the sets of possible plans for
![]() and
and
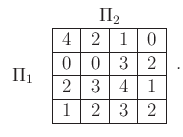
![]() , respectively. For the game in Figure 10.13,
, respectively. For the game in Figure 10.13, ![]() is a set of four possible plans for each player, which will be
specified in the following order:
is a set of four possible plans for each player, which will be
specified in the following order: ![]() ,
, ![]() ,
, ![]() , and
, and
![]() . These can be arranged into a
. These can be arranged into a
![]() matrix game:
matrix game:
The matrix-game form can also be derived for sequential games defined
under the stage-by-stage model. In this case, however, the space of
plans is even larger. For the example in Figure 10.13,
there are ![]() possible plans for each player (there are
possible plans for each player (there are ![]() decision
vertices for each player, at which two different actions can be applied;
hence,
decision
vertices for each player, at which two different actions can be applied;
hence,
![]() for
for ![]() and
and ![]() ). This results in a
). This results in a
![]() matrix game! This game should admit the same saddle point
solution that we already determined. The advantage of using the tree
representation is that this enormous game was decomposed into many
tiny matrix games. By treating the problem stage-by-stage,
substantial savings in computation results. This power arises because
the dynamic programming principle was implicitly used in the
tree-based computation method of decomposing the sequential game into
small matrix games. The connection to previous dynamic programming
methods will be made clearer in the next section, which considers
sequential games that are defined over a state space.
matrix game! This game should admit the same saddle point
solution that we already determined. The advantage of using the tree
representation is that this enormous game was decomposed into many
tiny matrix games. By treating the problem stage-by-stage,
substantial savings in computation results. This power arises because
the dynamic programming principle was implicitly used in the
tree-based computation method of decomposing the sequential game into
small matrix games. The connection to previous dynamic programming
methods will be made clearer in the next section, which considers
sequential games that are defined over a state space.
Steven M LaValle 2020-08-14