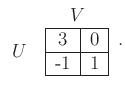Next: 9.4 Nonzero-Sum Games Up: 9.3.3 Randomized Strategies Previous: 9.3.3.1 Extending the formulation
So far it has been established that a randomized saddle point always exists, but how can one be found? Two key observations enable a combinatorial solution to the problem:
First consider the problem of determining the security strategy for
![]() . The first observation means that (9.59) does
not need to consider randomized strategies for
. The first observation means that (9.59) does
not need to consider randomized strategies for
![]() . Inside of the
. Inside of the
![]() ,
, ![]() is fixed. What randomized strategy,
is fixed. What randomized strategy, ![]() ,
maximizes
,
maximizes
![]() ? If
? If ![]() is fixed, then
is fixed, then ![]() can be
treated as a constant
can be
treated as a constant ![]() -dimensional vector,
-dimensional vector, ![]() . This means
. This means
![]() , in which
, in which ![]() is the inner (dot)
product. Now the task is to select
is the inner (dot)
product. Now the task is to select ![]() to maximize
to maximize ![]() . This
involves selecting the largest element of
. This
involves selecting the largest element of ![]() ; suppose this is
; suppose this is ![]() .
The maximum cost over all
.
The maximum cost over all ![]() is obtained by placing all of the
probability mass at action
is obtained by placing all of the
probability mass at action ![]() . Thus, the strategy
. Thus, the strategy ![]() and
and ![]() for
for ![]() gives the highest cost, and it is deterministic.
gives the highest cost, and it is deterministic.
Using the first observation, for each ![]() , only
, only ![]() possible
responses by
possible
responses by
![]() need to be considered. These are the
need to be considered. These are the ![]() deterministic strategies, each of which assigns
deterministic strategies, each of which assigns ![]() for a unique
for a unique
![]() .
.
Now consider the second observation. The expected cost,
![]() , is a linear function of
, is a linear function of ![]() , if
, if ![]() is fixed. Since
is fixed. Since ![]() only
needs to be fixed at
only
needs to be fixed at ![]() different values due to the first
observation,
different values due to the first
observation, ![]() is selected at the point at which the smallest
maximum value among the
is selected at the point at which the smallest
maximum value among the ![]() linear functions occurs. This is the
minimum value of the upper envelope of the collection of linear
functions. Such envelopes were mentioned in Section 6.5.2.
Example 9.16 will illustrate this. The domain for
this optimization can conveniently be set as a triangle in
linear functions occurs. This is the
minimum value of the upper envelope of the collection of linear
functions. Such envelopes were mentioned in Section 6.5.2.
Example 9.16 will illustrate this. The domain for
this optimization can conveniently be set as a triangle in
![]() . Even though
. Even though
![]() , the last coordinate,
, the last coordinate,
![]() , is not needed because it is always
, is not needed because it is always
![]() . The resulting optimization falls under linear
programming, for which many combinatorial algorithms exist
[259,264,664,731].
. The resulting optimization falls under linear
programming, for which many combinatorial algorithms exist
[259,264,664,731].
In the explanation above, there is nothing particular to
![]() when
trying to find its security strategy. The same method can be applied
to determine the security strategy for
when
trying to find its security strategy. The same method can be applied
to determine the security strategy for
![]() ; however, every
minimization is replaced by a maximization, and vice versa. In
summary, the
; however, every
minimization is replaced by a maximization, and vice versa. In
summary, the ![]() in (9.60) needs only to consider
the deterministic strategies in
in (9.60) needs only to consider
the deterministic strategies in ![]() . If
. If ![]() becomes fixed, then
becomes fixed, then
![]() is once again a linear function, but this time it
is linear in
is once again a linear function, but this time it
is linear in ![]() . The best randomized action is chosen by finding the
point
. The best randomized action is chosen by finding the
point ![]() that gives the highest minimum value among
that gives the highest minimum value among ![]() linear
functions. This is the minimum value of the lower envelope of
the collection of linear functions. The optimization occurs over
linear
functions. This is the minimum value of the lower envelope of
the collection of linear functions. The optimization occurs over
![]() because the last coordinate,
because the last coordinate, ![]() , is obtained directly
from
, is obtained directly
from
![]() .
.
This computation method is best understood through an example.
Consider computing the security strategy for
![]() . Note that
. Note that ![]() and
and
![]() are only one-dimensional subsets of
are only one-dimensional subsets of
![]() . A randomized
strategy for
. A randomized
strategy for
![]() is
is
![]() , with
, with
![]() ,
,
![]() , and
, and
![]() . Therefore, the domain over which the
optimization is performed is
. Therefore, the domain over which the
optimization is performed is
![]() because
because ![]() can always
be derived as
can always
be derived as
![]() . Using the first observation above,
only the two deterministic strategies for
. Using the first observation above,
only the two deterministic strategies for
![]() need to be considered.
When considered as linear functions of
need to be considered.
When considered as linear functions of ![]() , these are
, these are
| (9.64) |
| (9.65) |
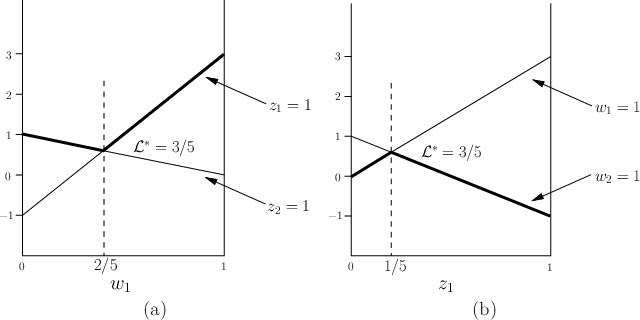 |
A similar procedure can be used to obtain ![]() . The lines that
correspond to the deterministic strategies of
. The lines that
correspond to the deterministic strategies of
![]() are shown in
Figure 9.4b. The security strategy is obtained by
finding the maximum value along the lower envelope of the lines, which
is shown as the thickened line in the figure. This results in
are shown in
Figure 9.4b. The security strategy is obtained by
finding the maximum value along the lower envelope of the lines, which
is shown as the thickened line in the figure. This results in
![]() , and once again, the value is observed as
, and once again, the value is observed as
![]() (this must coincide with the previous one because the randomized
upper and lower values are the same!).
(this must coincide with the previous one because the randomized
upper and lower values are the same!).
![]()
This procedure appears quite simple if there are only two actions per
player. If
![]() , then the upper and lower envelopes are
piecewise-linear functions in
, then the upper and lower envelopes are
piecewise-linear functions in
![]() . This may be computationally
impractical because all existing linear programming algorithms have
running time at least exponential in dimension [264].
. This may be computationally
impractical because all existing linear programming algorithms have
running time at least exponential in dimension [264].