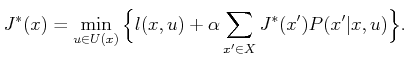Next: Policy iteration for discounted Up: 10.3.2 Solution Techniques Previous: 10.3.2 Solution Techniques
A backward value iteration solution will be presented that follows
naturally from the method given in Section 10.2.1. For
notational convenience, let the first stage be designated as ![]() so that
so that
![]() may be replaced by
may be replaced by ![]() . In the
probabilistic case, the expected optimal cost-to-go is
. In the
probabilistic case, the expected optimal cost-to-go is
Since the probabilistic case is more common, it will be covered here. The nondeterministic version is handled in a similar way (see Exercise 17). As before, backward value iterations will be performed because they are simpler to express. The discount factor causes a minor complication that must be fixed to make the dynamic programming recurrence work properly.
One difficulty is that the stage index now appears in the cost
function, in the form of ![]() . This means that the
shift-invariant property from Section 2.3.1 is no longer
preserved. We must therefore be careful about assigning stage
indices. This is a problem because for backward value iteration the
final stage index has been unknown and unimportant.
. This means that the
shift-invariant property from Section 2.3.1 is no longer
preserved. We must therefore be careful about assigning stage
indices. This is a problem because for backward value iteration the
final stage index has been unknown and unimportant.
Consider a sequence of discounted decision-making problems, by
increasing the maximum stage index: ![]() ,
, ![]() ,
, ![]() ,
, ![]() .
Look at the neighboring cost expressions in Figure 10.10.
What is the difference between finding the optimal cost-to-go for the
.
Look at the neighboring cost expressions in Figure 10.10.
What is the difference between finding the optimal cost-to-go for the
![]() -stage problem and the
-stage problem and the ![]() -stage problem? In Figure
10.10 the last four terms of the cost for
-stage problem? In Figure
10.10 the last four terms of the cost for ![]() can be
obtained by multiplying all terms for
can be
obtained by multiplying all terms for ![]() by
by ![]() and adding a
new term,
and adding a
new term, ![]() . The only difference is that the stage indices need
to be shifted by one on each
. The only difference is that the stage indices need
to be shifted by one on each ![]() that was borrowed from the
that was borrowed from the ![]() case. In general, the optimal costs of a
case. In general, the optimal costs of a ![]() -stage optimization
problem can serve as the optimal costs of the
-stage optimization
problem can serve as the optimal costs of the ![]() -stage problem if
they are first multiplied by
-stage problem if
they are first multiplied by ![]() . The
. The ![]() -stage optimization
problem can be solved by optimizing over the sum of the first-stage
cost plus the optimal cost for the
-stage optimization
problem can be solved by optimizing over the sum of the first-stage
cost plus the optimal cost for the ![]() -stage problem, discounted by
-stage problem, discounted by
![]() .
.
This can be derived using straightforward dynamic programming
arguments as follows. Suppose that ![]() is fixed. The cost-to-go can
be expressed recursively for
is fixed. The cost-to-go can
be expressed recursively for ![]() from 0 to
from 0 to ![]() as
as
The idea of using neighboring cost values as shown in Figure
10.10 can be applied by making a notational change. Let
![]() . This reverses the
direction of the stage indices to avoid specifying the final stage
and also scales by
. This reverses the
direction of the stage indices to avoid specifying the final stage
and also scales by
![]() to correctly compensate for the index
change. Substitution into (10.72) yields
to correctly compensate for the index
change. Substitution into (10.72) yields
Value iteration proceeds by first letting
![]() for all
for all ![]() . Successive cost-to-go functions are computed by iterating
(10.74) over the state space. Under the
cycle-avoiding assumptions of Section 10.2.1, the
convergence is usually asymptotic due to the infinite horizon. The
discounting gradually causes the cost differences to diminish until
they are within the desired tolerance. The stationary form of the
dynamic programming recurrence, which is obtained in the limit as
. Successive cost-to-go functions are computed by iterating
(10.74) over the state space. Under the
cycle-avoiding assumptions of Section 10.2.1, the
convergence is usually asymptotic due to the infinite horizon. The
discounting gradually causes the cost differences to diminish until
they are within the desired tolerance. The stationary form of the
dynamic programming recurrence, which is obtained in the limit as ![]() tends to infinity, is
tends to infinity, is
![$\displaystyle G^*(x) = \lim_{K \to \infty} \left( \min_{{\tilde{u}}} \left\{ E_...
...a}}} \left[ \sum_{k=1}^K \alpha^k l(x_k,u_k,\theta_k) \right] \right\} \right).$](img4158.gif)
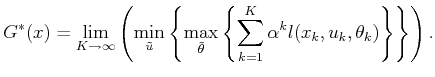
![$\displaystyle G^*_k({x_k}) = \min_{{u_k}\in U({x_k})} \Big\{ E_{{\theta_k}} \Big[ \alpha^k l({x_k},{u_k},{\theta_k}) + G^*_{k+1}(x_{k+1}) \Big] \Big\} ,$](img4164.gif)
![$\displaystyle \alpha^k J^*_{K-k}(x_k) = \min_{{u_k}\in U({x_k})} \Big\{ E_{{\th...
...^k l({x_k},{u_k},{\theta_k}) + \alpha^{k+1} J^*_{K-k-1}(x_{k+1}) \Big] \Big\} .$](img4167.gif)
![$\displaystyle J^*_i(x_k) = \min_{{u_k}\in U({x_k})} \Big\{ E_{{\theta_k}} \Big[ l({x_k},{u_k},{\theta_k}) + \alpha J^*_{i-1}(x_{k+1}) \Big] \Big\} ,$](img4169.gif)
![$\displaystyle J^*(x) = \min_{u \in U(x)} \Big\{ E_{{\theta_k}} \Big[ l(x,u,\theta) + \alpha J^*(f(x,u,\theta)) \Big] \Big\} .$](img4178.gif)