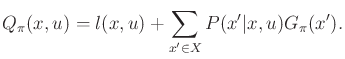Next: 10.5 Sequential Game Theory Up: 10.4.3 Q-Learning: Computing an Previous: Value iteration
A simulation-based policy iteration algorithm can be derived using
Q-factors. Recall from Section 10.2.2 that methods are
needed to: 1) evaluate a given plan, ![]() , and 2) improve the plan
by selecting better actions. The plan evaluation previously involved
linear equation solving. Now any plan,
, and 2) improve the plan
by selecting better actions. The plan evaluation previously involved
linear equation solving. Now any plan, ![]() , can be evaluated
without even knowing
, can be evaluated
without even knowing ![]() by using the methods of Section
10.4.2. Once
by using the methods of Section
10.4.2. Once
![]() is computed reliably from every
is computed reliably from every ![]() , further simulation can be used to compute
, further simulation can be used to compute
![]() for each
for each
![]() and
and ![]() . This can be achieved by defining a version
of (10.99) that is constrained to
. This can be achieved by defining a version
of (10.99) that is constrained to ![]() :
:
Steven M LaValle 2020-08-14