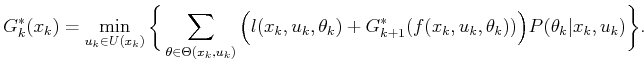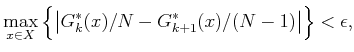Next: 10.4 Reinforcement Learning Up: 10.3.2 Solution Techniques Previous: Policy iteration for discounted
A value iteration algorithm for the average cost model can be obtained
by simply neglecting to divide by ![]() . Selecting actions that
optimize the total cost also optimizes the average cost as the number
of stages approaches infinity. This may cause costs to increase
toward
. Selecting actions that
optimize the total cost also optimizes the average cost as the number
of stages approaches infinity. This may cause costs to increase
toward
![]() ; however, only a finite number of iterations can
be executed in practice.
; however, only a finite number of iterations can
be executed in practice.
The backward value iterations of Section 10.2.1 can be
followed with very little modification. Initially, let
![]() for all
for all ![]() . The value iterations are computed using the
standard form
. The value iterations are computed using the
standard form
A numerical problem may exist with the growing values obtained for
![]() . This can be alleviated by periodically reducing all
values by some constant factor to ensure that the numbers fit within
the allowable floating point range. In [96], a method called
relative value iteration is
presented, which selects one state,
. This can be alleviated by periodically reducing all
values by some constant factor to ensure that the numbers fit within
the allowable floating point range. In [96], a method called
relative value iteration is
presented, which selects one state, ![]() , arbitrarily and
expresses the cost-to-go values by subtracting off the cost at
, arbitrarily and
expresses the cost-to-go values by subtracting off the cost at ![]() .
This trims down all values simultaneously to keep them bounded while
still maintaining the convergence properties of the algorithm.
.
This trims down all values simultaneously to keep them bounded while
still maintaining the convergence properties of the algorithm.
Policy iteration can alternatively be performed by using the method given in Figure 10.4 with only minor modification.