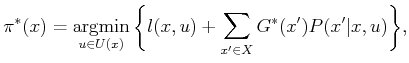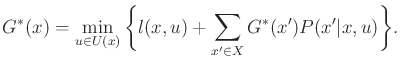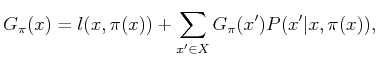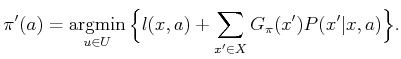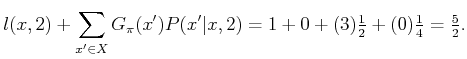Next: 10.2.3 Graph Search Methods Up: 10.2 Algorithms for Computing Previous: Using the plan
The value iterations of Section 10.2.1 work by iteratively
updating cost-to-go values on the state space. The optimal plan can
alternatively be obtained by iteratively searching in the space of
plans. This leads to a method called policy iteration
[84]; the term policy is synonymous with plan.
The method will be explained for the case of probabilistic
uncertainty, and it is assumed that ![]() is finite. With minor
adaptations, a version for nondeterministic uncertainty can also be
developed.
is finite. With minor
adaptations, a version for nondeterministic uncertainty can also be
developed.
Policy iteration repeatedly requires computing the cost-to-go for a
given plan, ![]() . Recall the definition of
. Recall the definition of ![]() from
(10.32). First suppose that there are no uncertainties,
and that the state transition equation is
from
(10.32). First suppose that there are no uncertainties,
and that the state transition equation is
![]() . The
dynamic programming equation (2.18) from Section
2.3.2 can be used to derive the cost-to-go for each state
. The
dynamic programming equation (2.18) from Section
2.3.2 can be used to derive the cost-to-go for each state ![]() under the application of
under the application of ![]() . Make a copy of
(2.18) for each
. Make a copy of
(2.18) for each ![]() , and instead of the
, and instead of the ![]() , use
the given action
, use
the given action
![]() , to yield
, to yield
If there are ![]() states, (10.50) yields
states, (10.50) yields ![]() equations,
each of which gives an expression of
equations,
each of which gives an expression of
![]() for a different
state. For the states in which
for a different
state. For the states in which
![]() , it is known that
, it is known that
![]() . Now that this is known, the cost-to-go for all
states from which
. Now that this is known, the cost-to-go for all
states from which ![]() can be reached in one stage can be computed
using (10.50) with
can be reached in one stage can be computed
using (10.50) with
![]() . Once
these cost-to-go values are computed, another wave of values can be
computed from states that can reach these in one stage. This process
continues until the cost-to-go values are computed for all states.
This is similar to the behavior of Dijkstra's algorithm.
. Once
these cost-to-go values are computed, another wave of values can be
computed from states that can reach these in one stage. This process
continues until the cost-to-go values are computed for all states.
This is similar to the behavior of Dijkstra's algorithm.
This process of determining the cost-to-go should not seem too
mysterious. Equation (10.50) indicates how the costs
differ between neighboring states in the state transition graph.
Since all of the differences are specified and an initial condition
is given for ![]() , all others can be derived by adding up the
differences expressed in (10.50). Similar ideas appear in
the Hamilton-Jacobi-Bellman equation and Pontryagin's minimum principle, which are covered in Section 15.2.
, all others can be derived by adding up the
differences expressed in (10.50). Similar ideas appear in
the Hamilton-Jacobi-Bellman equation and Pontryagin's minimum principle, which are covered in Section 15.2.
Now we turn to the case in which there are probabilistic
uncertainties. The probabilistic analog of (2.18) is
(10.49). For simplicity, consider the special case in
which
![]() does not depend on
does not depend on ![]() , which results in
, which results in
The cost-to-go for each ![]() under the application of
under the application of ![]() can be determined by writing (10.53) for each state.
Note that all quantities except
can be determined by writing (10.53) for each state.
Note that all quantities except ![]() are known. This means that
if there are
are known. This means that
if there are ![]() states, then there are
states, then there are ![]() linear equations and
linear equations and ![]() unknowns (
unknowns (![]() for each
for each ![]() ). The same was true when
(10.50) was used, except the equations were much simpler.
In the probabilistic setting, a system of
). The same was true when
(10.50) was used, except the equations were much simpler.
In the probabilistic setting, a system of ![]() linear equations must be
solved to determine
linear equations must be
solved to determine ![]() . This may be performed using classical
linear algebra techniques, such as singular value decomposition
(SVD) [399,961].
. This may be performed using classical
linear algebra techniques, such as singular value decomposition
(SVD) [399,961].
 |
Now that we have a method for evaluating the cost of a plan, the
policy iteration method is straightforward, as specified in Figure
10.4. Note that in Step 3, the cost-to-go ![]() ,
which was developed for one plan,
,
which was developed for one plan, ![]() , is used to evaluate other
plans. The result is the cost that will be obtained if a new action
is tried in the first stage and then
, is used to evaluate other
plans. The result is the cost that will be obtained if a new action
is tried in the first stage and then ![]() is used for all
remaining stages. If a new action cannot reduce the cost, then
is used for all
remaining stages. If a new action cannot reduce the cost, then
![]() must have already been optimal because it means that
(10.54) has become equivalent to the stationary dynamic
programming equation, (10.49). If it is possible to
improve
must have already been optimal because it means that
(10.54) has become equivalent to the stationary dynamic
programming equation, (10.49). If it is possible to
improve ![]() , then a new plan is obtained. The new plan must be
strictly better than the previous plan, and there is only a finite
number of possible plans in total. Therefore, the policy iteration
method converges after a finite number of iterations.
, then a new plan is obtained. The new plan must be
strictly better than the previous plan, and there is only a finite
number of possible plans in total. Therefore, the policy iteration
method converges after a finite number of iterations.
 |
Now use (10.53) to compute ![]() . This yields three
equations:
. This yields three
equations:
| (10.54) | ||
| (10.55) | ||
| (10.56) |
| (10.57) |
| (10.58) |
Now use (10.54) for each state with
![]() and
and
![]() to find a better plan,
to find a better plan,
![]() . At state
. At state ![]() , it
is found by solving
, it
is found by solving
Since an improved plan has been found, replace ![]() with
with
![]() and return to Step 2. The new plan yields the
equations
and return to Step 2. The new plan yields the
equations
| (10.61) |
| (10.62) |
Policy iteration may appear preferable to value iteration, especially
because it usually converges in fewer iterations than value iteration.
The equation solving that determines the cost of a plan effectively
considers multiple stages at once. However, for most planning
problems, ![]() is large and the large linear system of equations that
must be solved at every iteration can become unwieldy. In some
applications, either the state space may be small enough or sparse
matrix techniques may allow efficient solutions over larger state
spaces. In general, value-based methods seem preferable for most
planning problems.
is large and the large linear system of equations that
must be solved at every iteration can become unwieldy. In some
applications, either the state space may be small enough or sparse
matrix techniques may allow efficient solutions over larger state
spaces. In general, value-based methods seem preferable for most
planning problems.
Steven M LaValle 2020-08-14