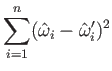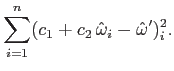Next: Integration Up: 9.1 Tracking 2D Orientation Previous: 9.1 Tracking 2D Orientation Contents Index
You could buy a sensor and start using it with the assumption that it is already well calibrated. For a cheaper sensor, however, the calibration is often unreliable. Suppose we have one expensive, well-calibrated sensor that reports angular velocities with very little error. Let
![]() denote its output, to distinguish it from the forever unknown true value
denote its output, to distinguish it from the forever unknown true value ![]() . Now suppose that we want to calibrate a bunch of cheap sensors so that they behave as closely as possible to the expensive sensor. This could be accomplished by mounting them together on a movable surface and comparing their outputs. For greater accuracy and control, the most expensive sensor may be part of a complete mechanical system such as an expensive turntable, calibration rig, or robot. Let
. Now suppose that we want to calibrate a bunch of cheap sensors so that they behave as closely as possible to the expensive sensor. This could be accomplished by mounting them together on a movable surface and comparing their outputs. For greater accuracy and control, the most expensive sensor may be part of a complete mechanical system such as an expensive turntable, calibration rig, or robot. Let
![]() denote the output of one cheap sensor to be calibrated; each cheap sensor must be calibrated separately.
denote the output of one cheap sensor to be calibrated; each cheap sensor must be calibrated separately.
Calibration involves taking many samples, sometimes thousands, and comparing
![]() to
to
![]() . A common criterion is the sum of squares error, which is given by
. A common criterion is the sum of squares error, which is given by
Using the error model from (9.1), we can select constants ![]() and
and ![]() that optimize the error:
that optimize the error:
Once ![]() and
and ![]() are calculated, every future sensor reading is transformed as
are calculated, every future sensor reading is transformed as