Next: 10.5.1.1 Determining a security Up: 10.5 Sequential Game Theory Previous: 10.5 Sequential Game Theory
In most literature, sequential games are formulated in terms of game trees. A state-space representation, which is more in alignment with the representations used in this chapter, will be presented in Section 10.5.2. The tree representation is commonly referred to as the extensive form of a game (as opposed to the normal form, which is the cost matrix representation used in Chapter 9). The representation is helpful for visualizing many issues in game theory. It is perhaps most helpful for visualizing information states; this aspect of game trees will be deferred until Section 11.7, after information spaces have been formally introduced. Here, game trees are presented for cases that are simple to describe without going deeply into information spaces.
Before a sequential game is introduced, consider representing a
single-stage game in a tree form. Recall Example 9.14,
which is a zero-sum,
![]() matrix game. It can be represented
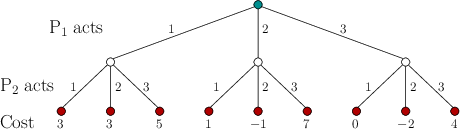
as a game tree as shown in Figure 10.12. At the
root,
matrix game. It can be represented
as a game tree as shown in Figure 10.12. At the
root,
![]() has three choices. At the next level,
has three choices. At the next level,
![]() has three
choices. Based on the choices by both, one of nine possible leaves
will be reached. At this point, a cost is obtained, which is written
under the leaf. The entries of the cost matrix,
(9.53), appear across the leaves of the tree. Every
nonleaf vertex is called a decision vertex: One player must select an action.
has three
choices. Based on the choices by both, one of nine possible leaves
will be reached. At this point, a cost is obtained, which is written
under the leaf. The entries of the cost matrix,
(9.53), appear across the leaves of the tree. Every
nonleaf vertex is called a decision vertex: One player must select an action.
There are two possible interpretations of the game depicted in Figure 10.12:
Now imagine that
![]() and
and
![]() play a sequence of games. A
sequential version of the zero-sum game from Section 9.3
will be defined by extending the game tree idea given so far to more
levels. This will model the following sequential game:
play a sequence of games. A
sequential version of the zero-sum game from Section 9.3
will be defined by extending the game tree idea given so far to more
levels. This will model the following sequential game:
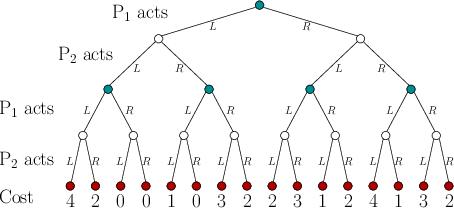
The game tree can now be described in detail. Figure
10.13 shows a particular example for two stages (hence, ![]() and
and
![]() ). Every vertex corresponds to a point at
which a decision needs to be made by one player. Each edge emanating
from a vertex represents an action. The root of the tree indicates
the beginning of the game, which usually means that
). Every vertex corresponds to a point at
which a decision needs to be made by one player. Each edge emanating
from a vertex represents an action. The root of the tree indicates
the beginning of the game, which usually means that
![]() chooses an
action. The leaves of the tree represent the end of the game, which
are the points at which a cost is received. The cost is usually shown
below each leaf. One final concern is to specify the information
available to each player, just prior to its decision. Which actions
among those previously applied by itself or other players are known?
chooses an
action. The leaves of the tree represent the end of the game, which
are the points at which a cost is received. The cost is usually shown
below each leaf. One final concern is to specify the information
available to each player, just prior to its decision. Which actions
among those previously applied by itself or other players are known?
For the game tree in Figure 10.13, there are two players and
two stages. Therefore, there are four levels of decision vertices. The
action sets for the players are
![]() , for ``left'' and
``right.'' Since there are always two actions, a binary tree is
obtained. There are
, for ``left'' and
``right.'' Since there are always two actions, a binary tree is
obtained. There are ![]() possible outcomes, which correspond to all
pairwise combinations of four possible two-stage plans for each
player.
possible outcomes, which correspond to all
pairwise combinations of four possible two-stage plans for each
player.
For a single-stage game, both deterministic and randomized strategies were defined to obtain saddle points. Recall from Section 9.3.3 that randomized strategies were needed to guarantee the existence of a saddle point. For a sequential game, these are extended to deterministic and randomized plans, respectively. In Section 10.1.3, a (deterministic) plan was defined as a mapping from the state space to an action space. This definition can be applied here for each player; however, we must determine what is a ``state'' for the game tree. This depends on the information that each player has available when it plays.
A general framework for representing information in game trees is covered in Section 11.7. Three simple kinds of information will be discussed here. In every case, each player knows its own actions that were applied in previous stages. The differences correspond to knowledge of actions applied by the other player. These define the ``state'' that is used to make the decisions in a plan.
The three information models considered here are as follows.