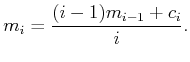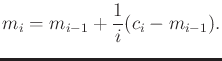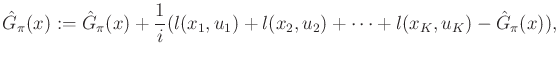Next: Temporal differences Up: 10.4 Reinforcement Learning Previous: The general framework
The simulation method is based on averaging the information gained
incrementally from samples. Suppose that you receive a sequence of
costs, ![]() ,
, ![]() ,
, ![]() , and would like to incrementally compute
their average. You are not told the total number of samples in
advance, and at any point you are required to report the current
average. Let
, and would like to incrementally compute
their average. You are not told the total number of samples in
advance, and at any point you are required to report the current
average. Let ![]() denote the average of the first
denote the average of the first ![]() samples,
samples,
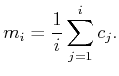 |
(10.80) |
Now consider the problem of estimating the expected cost-to-go,
![]() , at every
, at every ![]() for some fixed plan,
for some fixed plan, ![]() . If
. If
![]() and the costs
and the costs ![]() were known, then it could be
computed by solving
were known, then it could be
computed by solving
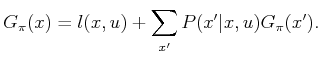 |
(10.83) |
From each ![]() , suppose that
, suppose that ![]() trials are conducted, and
the resulting costs to get to the goal are recorded and averaged.
Each trial is an iterative process in which
trials are conducted, and
the resulting costs to get to the goal are recorded and averaged.
Each trial is an iterative process in which ![]() selects the
action, and the simulator indicates the next state and its incremental
cost. Once the goal state is reached, the costs are totaled to yield
the measured cost-to-go for that trial (this assumes that
selects the
action, and the simulator indicates the next state and its incremental
cost. Once the goal state is reached, the costs are totaled to yield
the measured cost-to-go for that trial (this assumes that
![]() for all
for all
![]() ). If
). If ![]() denotes this total cost at
trial
denotes this total cost at
trial ![]() , then the average,
, then the average, ![]() , over
, over ![]() trials provides an
estimate of
trials provides an
estimate of ![]() . As
. As ![]() tends to infinity, we expect
tends to infinity, we expect ![]() to converge to
to converge to ![]() . The update formula (10.83)
can be conveniently used to maintain the improving sequence of
cost-to-go estimates. Let
. The update formula (10.83)
can be conveniently used to maintain the improving sequence of
cost-to-go estimates. Let
![]() denote the current estimate of
denote the current estimate of
![]() . The update formula based on (10.83) can be
expressed as
. The update formula based on (10.83) can be
expressed as
It turns out that a single trial can actually yield update values for
multiple states [930,96]. Suppose that a trial is
performed from ![]() that results in the sequence
that results in the sequence ![]() ,
, ![]() ,
,
![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() of visited states. For every
state,
of visited states. For every
state, ![]() , in the sequence, a cost-to-go value can be measured by
recording the cost that was accumulated from
, in the sequence, a cost-to-go value can be measured by
recording the cost that was accumulated from ![]() to
to ![]() :
:
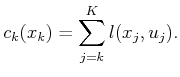 |
(10.85) |